[JavaScript] Promiseを完全に理解する
初めに
なんとなくで理解していたPromiseを完全に理解した状態を目指したいと思い、調べたことを備忘録として残しておきたいと思います。
前提
JavaScriptは非同期処理になります。処理を待たずに次の処理に移っていくため、例えば以下のようなコードだと
let count = 0 setTimeout(() => { for(let i = 0; i < 10; i++) { count += i } }, 3000) console.log(count) // => 実行結果 0
理想は、for文の処理を待ってから出力してほしいですが、 非同期処理なので、このような結果となります。
本題
Promise
前提のような処理結果を待って、その後に次に進みたいといった時に、Promiseは活躍します。
処理がうまくいったのか?それとも失敗したのか?
Promiseは処理の結果を返すようになります。このことを「プロミスを返す」と言います。
プロミスの状態
処理結果を返すために、プロミスは状態を扱います。状態は以下の3つのいずれかです。
pending・・・待機
new Promise()で作られたPromiseオブジェクトは、pendingというPromiseStatusで作られます。いわゆる初期状態で何も処理がされていません。resolved・・・履行(完了)
処理が終わり、成功した状態です。resolve()メソッドを使用して返します。
rejected・・・拒否(失敗)
処理が失敗した状態です。reject()メソッドを使用して返します。
初めはpendingですが、メソッドを活用してpromiseの状態をresolved, rejectedのどちらかに変化させます。
then()メソッド・catch()メソッド
- then()・・・resolvedになると実行するハンドラー
- catch()・・・rejectedになると実行するハンドラー
Ex. resolved
let count = 0 const addPromise = new Promise((resolve, reject) => { setTimeout(() => { for(let i = 0; i < 10; i++) { count += i } resolve() }, 3000) }) addPromise.then(() => { console.log(count) }) // => 実行結果 45
冒頭に挙げたコードに、Promiseを使用してみました。
addPromiseにnew Promiseでプロミスオブジェクトを代入し、行いたい処理(ここではfor文)を記述します。処理が終わったら、resolve()メソッドを呼び出しPromiseの状態をresolvedに変化させます。
addPromiseをresolvedに変化させた結果、then()メソッドが実行され、きちんとfor文の処理が終わった45が出力されるようになります。
Ex. rejected
rejectedもresolvedと同じ形で使用できます。コードもあえて同じ処理にはしていますが、本来エラー用の処理を記述します。
let count = 0 const addPromise = new Promise((resolve, reject) => { setTimeout(() => { for(let i=0; i < 10; i++) { count += i } reject() }, 3000) }) addPromise.catch(() => { console.log(count) }) // => 実行結果 45
処理結果を返したい
また処理結果を返したいときは、resolve()メソッドに値を渡すことで返すことができます。reject()メソッドも同様の形で使用できます。
const addPromise = new Promise((resolve) => { setTimeout(() => { let count = 0 for(let i=0; i < 10; i++) { count += i } resolve(count) }, 3000) }) addPromise.then((count) => { console.log(count) }) // => 実行結果 45
繋げる
以下のような形でthen()メソッド、catch()メソッドをピリオドを用いて繋げて書くこともできます。
const addPromise = new Promise((resolve, reject) => { setTimeout(() => { let count = 0 for(let i=0; i < 10; i++) { count += i } resolve(count) }, 3000) }).then((count) => { console.log(count) }).catch(() => { console.log('error') }) // => 実行結果 45
Promise.all()メソッド
複数のpromiseオブジェクトを配列で渡し、全てのPromiseからの処理結果を待ちます
const promise1 = new Promise((resolve, reject) => { resolve(10) }) const promise2 = new Promise((resolve, reject) => { setTimeout(() => { resolve(20) }, 1000) }) const promise3 = new Promise((resolve, reject) => { setTimeout(() => { resolve(30) }, 2000) }) Promise.all([promise1, promise2, promise3]).then((values) => { console.log(values) }) // => 実行結果 [ 10, 20, 30 ]
補足
then()メソッド
本題にてthen()メソッド内では、resolvedになると実行するハンドラーと書きましたが、rejectedの時にも処理はできます。厳密には、thenメソッドの中の処理が成功時は、onFulfilled、失敗時はonRejectedがそれぞれ呼び出されるようになっています。
catch()メソッドはこのonRejectedメソッドを呼び出しているのだそうです。
個人的には、then()はresolved, catch()はrejectedという認識だけで、問題ないかと思います。
catch() メソッドは Promise を返しますが、拒否された場合のみ扱います。 Promise.prototype.then(undefined, onRejected) の呼び出しと同じ動作をします(実際、 obj.catch(onRejected) の呼び出しは内部的に obj.then(undefined, onRejected) を呼び出しています)
参考
[Python] venvから仮想環境を作成する
初めに
筆者は、6月中旬より未経験から自社開発企業のWebエンジニアになることができた。ただこれまでRubyを中心に学習してきたが、実務ではメイン言語がPythonになったので、現在新しくキャッチアップしているところである。
今回はその中で、仮想環境・venvについて取り上げる。
仮想環境・venvとは
Python を使って開発や実験を行うときは、用途に応じて専用の実行環境を作成し、切り替えて使用するのが一般的です。こういった、一時的に作成する実行環境を、「仮想環境」 と言います。*1
上記の仮想環境を、Pythonではvenvを使用する
bundler --pathに近い?
Railsでいうところのbundlerの仕組みの一部分に近いのではないかと思う。bundlerは、Gemパッケージの管理ツールであり、installする際に--path vendor/bundle を使用することで、プロジェクト別にgemを管理することができる。
bundlerでは仮想環境という表現はしないものの、「プロジェクトごとに依存関係にあるパッケージを管理する」という意味合いで近いのではないか。
venvで実際に仮想環境を作成する
※macOS。事前にpython, pipはインストール済み
新しいプロジェクト下で、仮想環境作成用のファイルを作成する
(base) % python3 -m venv venv(名前は任意)
- venvファイルが作成される
仮想環境の中に入る source venv/bin/activate
(base) % source venv/bin/activate (venv) (base) %
source venv/bin/activateとすると、2行目より(venv)と表示され、仮想環境に入ったことがわかる
仮想環境の中でDjango4.0をインストールする
(venv) (base) % python3 -m pip install Django==4.0 % python3 -m django --version #=> 4.0
仮想環境を抜ける deactivate
(venv) (base) % deactivate (base) python3 -m django --version #=> No module named django
deactivateで2行目より、(venv)が消え仮想環境から抜けたことがわかる- djangoのバージョンを確認するコマンドも、存在しないと返されてしまい、仮想環境下でインストールできていたことがわかる
参考
JavaScriptのパッケージ管理 npm・Yarn・package.json
初めに
今回は普段なんとなく使用していた、JavaScriptのパッケージ管理を担っているnpm、Yarn、package.jsonについて、整理したいと思う。
前提
npmレジストリ
npmレジストリは、サーバーサイド側(Node.js)とブラウザ側の両方で使用できる、JavaScriptのパッケージレジストリのこと。Rubyでいう、rubygems.orgと似ている。webpackも、このnpmレジストリにあるパッケージの一つである。
※一般的にはnpmと称されるが、CLI上で使用されるnpmと分けるため、本記事ではnpmレジストリとする。
本題
package.json
アプリケーションの依存関係にある、npmレジストリのパッケージに関する情報を記録するためのファイル。RailsのGemfileと似ている。
rails newをすると、以下のようなディレクトリの構成になる。
(Rails バージョン6.0.5)
{ "name": "hoge", "private": true, "dependencies": { "@rails/actioncable": "^6.0.0", "@rails/activestorage": "^6.0.0", "@rails/ujs": "^6.0.0", "@rails/webpacker": "4.3.0", "turbolinks": "^5.2.0" }, "version": "0.1.0", "devDependencies": { "webpack-dev-server": "^4.9.0" } }
dependencies
使用するnpmレジストリのパッケージを記述していく。
パッケージ名と、バージョン(範囲)を指定し、定義する。gitのURLで定義することもできる。
devDependencies
本番環境で使用しないパッケージは、こちらで定義する。
またscriptを用いて、スクリプトを定義することができる。
Ex.
... "devDependencies": { "webpack-dev-server": "^4.9.0" }, "scripts": { "grint": "echo Hello!" }
% yarn run grint #=> yarn run v1.22.11 $ echo Hello! Hello! ✨ Done in 0.05s.
npm
npm Inc社が2010年に開発したJavaScriptのパッケージマネージャーの一つである。
- Node.jsをインストールをすると、自動でインストールされるようになっている
package.jsonに書かれているnpmレジストリのパッケージを、依存関係を解決してインストールしてくれる。- インストールされたパッケージのバージョンは
package-lock.jsonに記載される - インストールしたパッケージは、
node_modulesディレクトリに格納される。
Yarn
Facebookが2016年に開発した、npmに並ぶJavaScriptパッケージマネージャの一つ。
- npmレジストリにあるパッケージの一つのため、npm経由でインストールする
- npmと互換性があるため、npmと同様に
package.jsonの記述を参照し、インストールする - インストールされたパッケージのバージョンは
yarn.lockに記載される - インストールしたパッケージは、npmと同様に
node_modulesディレクトリに格納される。
npmとYarnの違い
当初npmではパッケージの依存関係の管理がなく、セキュリティ上でも問題があったためにYarnが開発されたとのことだが、現在はnpmがYarnの機能を取り入れている(先に挙げたpackage-lock.json等)ため、現在は、ほぼ差はないとのこと。
参考
[Ruby] ループ処理のまとめ
初めに
アルゴリズムについて学習を進めていく中で、ループ処理を扱うことが多く、一度整理するためにまとめておく
本題
for
- 配列の要素や範囲オブジェクトの範囲分同じ処理を繰り返したい時に使用する
numbers = [1,2,3] for i in numbers p i end #=> 1 2 3
each
- 配列、範囲オブジェクトやハッシュで使用できるメソッドで、オブジェクトに含まれる要素を順番に取得したいときに使用する
numbers = [1,2,3] numbers.each do |num| p num end #=> 1 2 3
map(collect)
- 配列の要素の数だけブロック内の処理を繰り返し、結果として作成された配列を返す
- colllectはmapのエイリアス
numbers = [1,2,3] numbers.map do |num| p num end # => 1 2 3
※補足 eachとmapの違い
ブロック内の処理結果を返しているかどうか
each
numbers = [1,2,3] dobule_numbers = numbers.each do |num| num * 2 end p dobule_numbers #=> [1, 2, 3]
eachでは、ブロック内での処理結果は返されず、元の配列(numbers)の値と変わらないことがわかる
map
numbers = [1,2,3] dobule_numbers = numbers.map do |num| num * 2 end p dobule_numbers #=> [2, 4, 6]
mapでは、ブロック内での処理結果を返していることがわかる
while
- 指定した条件がtrueである間ループする
- forやeachと 違う点は、条件式がfalseになるまで、処理を繰り返し行うこと
number = 0 while number < 5 do p number number += 1 end #=> 0 1 2 3 4
until
指定した条件がfalseの間ループする
number = 5 until number < 2 do p number number -= 1 end #=> 5 4 3 2
loop
- breakで終了させない限りループし続ける
- if文と組み合わせてbreakを使用する
number = 0 loop do p number number += 1 if number > 5 break end end #=> 0 1 2 3 4 5
times
- 任意の回数分だけループさせるときに使用する
- ブロックには、[指定した回数 - 1 ]までの値が渡される
4.times do |i| p i end #=> 0 1 2 3
upto
- レシーバーから引数で指定した値までに到達するループを行い、その間にブロックに渡される値は、1ずつ増加する
- [ レシーバー > 引数 ]の場合、何も処理されない
1.upto(3) do |num| p num end #=> 1 2 3
downto
- uptoと反対の挙動をとる。ブロックに渡される値は、1ずつ減少する
3.downto(1) do |num| p num end #=> 3 2 1
参考
procとlambdaの違い
初めに
今回はRails開発者が採用面接で聞かれる想定Q&A 53問(翻訳)の中から、procとlambdaの違いについての問いがあり、こちらについて掘り下げていく
前提
procとlambdaの共通点
- procもlambdaも、どちらもブロックをオブジェクト化したものであり、Procクラスのインスタンスである
# proc proc1 = Proc.new { p "procインスタンス"} proc1.call #=> "procインスタンス" p "procは#{proc1.class}クラスです" #=> "procはProcクラスです"
# lambda lambda1 = lambda { p "lambdaインスタンス" } lambda1.call #=> "lambdaインスタンス" p "lambdaは#{lambda1.class}クラスです" #=> "lambdaはProcクラスです"
ブロック(block)
do ~ endあるいは{}で囲まれたもの- ブロック単体で存在することはできない
- 引数として渡されたブロックは
yieldによって実行される
本題(procとlambdaの違い)
1. 引数の数
procは想定される引数の数が違っていても、エラーが起きないが、lambdaではエラーが起きる
# proc proc1 = Proc.new { |a,b,c| p a,b,c} proc1.call(2,4) #=> 2 4 nil
# lambda lambda1 = lambda { |a,b,c| p a,b,c} lambda1.call(2,4) #=> Traceback (most recent call last): 1: from block.rb:5:in `<main>' block.rb:4:in `block in <main>': wrong number of arguments (given 2, expected 3) (ArgumentError)
procでは受け取っていない値はnilとなり、エラーは発生していないが、lambdaではエラーが発生していることがわかる
2. ジャンプ構文(return, break)の挙動の違い
procの場合は、returnやbreakが呼び出された場合、呼び出されたメソッドを抜ける挙動になる
# proc def test_proc proc1 = Proc.new { return p "returnが呼び出されました"} proc1.call p "処理は終了です" end test_proc #=> "returnが呼び出されました"
# lambda def test_lambda lambda1 = lambda { return p "returnが呼び出されました"} lambda1.call p "処理は終了です" end test_lambda #=> "returnが呼び出されました" #=> "処理は終了です"
procは
"処理は終了です"の出力がなく、メソッドを抜けていることがわかる
参考
[Ruby] アクセス制御の種類 public, private, protected
初めに
今回はRubyの3段階のアクセス制御であるpublic、private、protectedについて掘り下げる。
本題
public
制限なしに呼び出すことができる。クラス内ではデフォルトでpublic定義される。
class User def hello p "こんにちは" end user = User.new user.hello # => "こんにちは" end
private
関数形式(メソッド定義内)でしか呼び出すことができない。
クラス外ではデフォルトでprivate定義される。
(今回はclass内でModule#privateを用いてprivateに変更する)
class User def greeting morning end private def morning p "おはよう" end user = User.new user.morning # => ... `<class:User>': private method `morning' called for #<User:0x00007fd579907b20> (NoMethodError) user.greeting # => "おはよう" end
private下の
morningメソッドを直接呼び出すと、エラーが発生するがgreetingメソッド内では呼び出すことができる
protected
レシーバーが同クラスか、サブクラスであれば呼び出すことができる
class User def set_name(name) @name = name end def greet(user) p "#{get_name}さんが#{user.get_name}さんに挨拶しました" end protected def get_name @name end user_1 = User.new user_1.set_name("佐藤") user_2 = User.new user_2.set_name("鈴木") user_1.greet(user_2) #=> "佐藤さんが鈴木さんに挨拶しました" end
protectedをprivateに変更する
private def get_name @name end ... user_1.greet(user_2) # => user.rb:7:in `greet': private method `get_name' called for #<User:0x00007feafc03f5b8 @name="鈴木"> (NoMethodError) ... end
protectedの部分をprivateに変更すると、エラーが発生する。privateであると引数にわたっている
userからは、同クラスでも呼び出すことができない。
参考
[Ruby on Rails]Ajaxを実現しているデフォルトのJavaScript機能
初めに
今回はRuby on Railsで元々組み込まれているもので、Ajax通信を実現しているJavaScriptの機能について掘り下げる
前提
Ajax
「Asynchronous JAvaScript + XML」の略。JavaScriptとXMLを用いてサーバー側との通信を「非同期」で行い、通信結果によって動的にページの一部だけ書き換える手法のこと
非同期通信
コンピュータ間で、送信者のデータ送信タイミングと受信者のデータ受信タイミングを合わせずに通信を行う通信方式
非同期通信であれば、送信者は受信を待たずして続けてリクエストを送ることもできる。他の処理を並行して行えるのが強み
rails new した時のpackage.json
以下のような構成となっている。
今回はAjaxを実現しているrails/ujs、turolinksについて掘り下げていく。
... "dependencies": { "@rails/actioncable": "^6.0.0", "@rails/activestorage": "^6.0.0", "@rails/ujs": "^6.0.0", "@rails/webpacker": "4.3.0", "turbolinks": "^5.2.0" },
本題
1.rails-ujs
画面の制御を補助するライブラリ。役割は以下の二つ
1. link_toなどのヘルパーメソッドに、data属性を付与することで確認ダイアログや二重送信防止の機能を実装できる
Ex. form_withに、確認ダイアログ機能を実装する
<div class="actions"> <%= form.submit data: { confirm: 'ユーザー作成してもよろしいですか?'} %> </div>
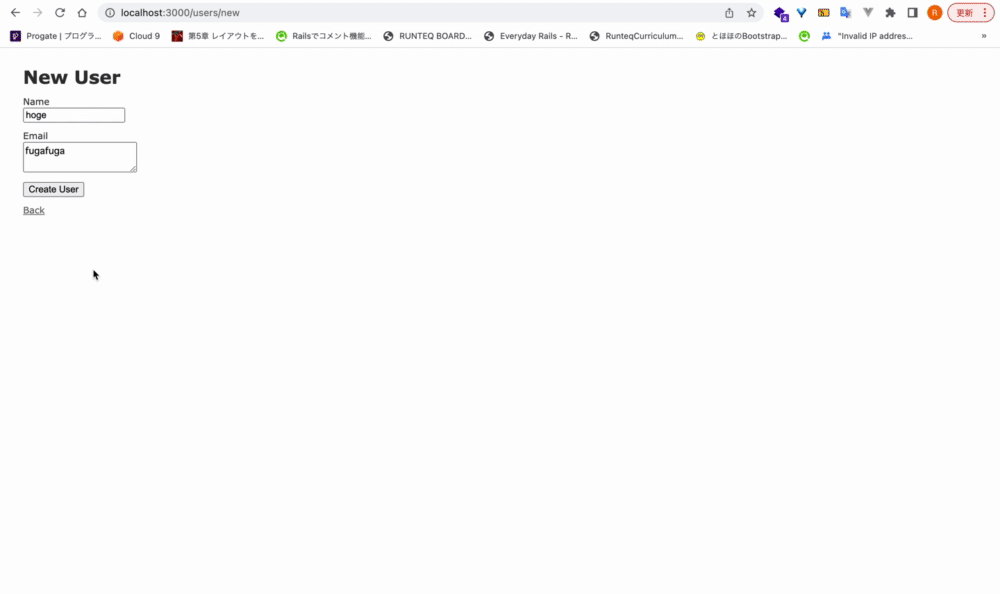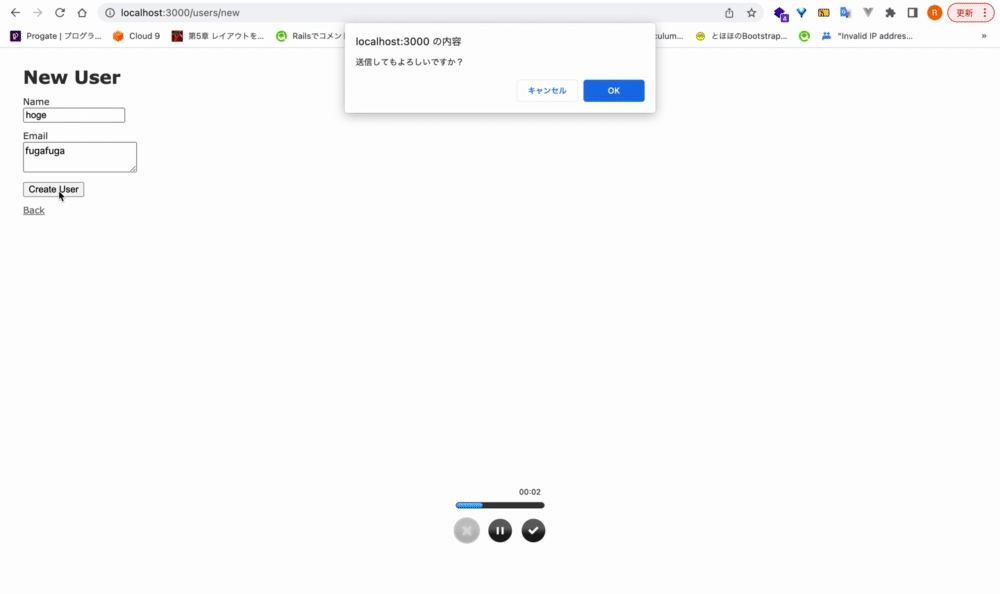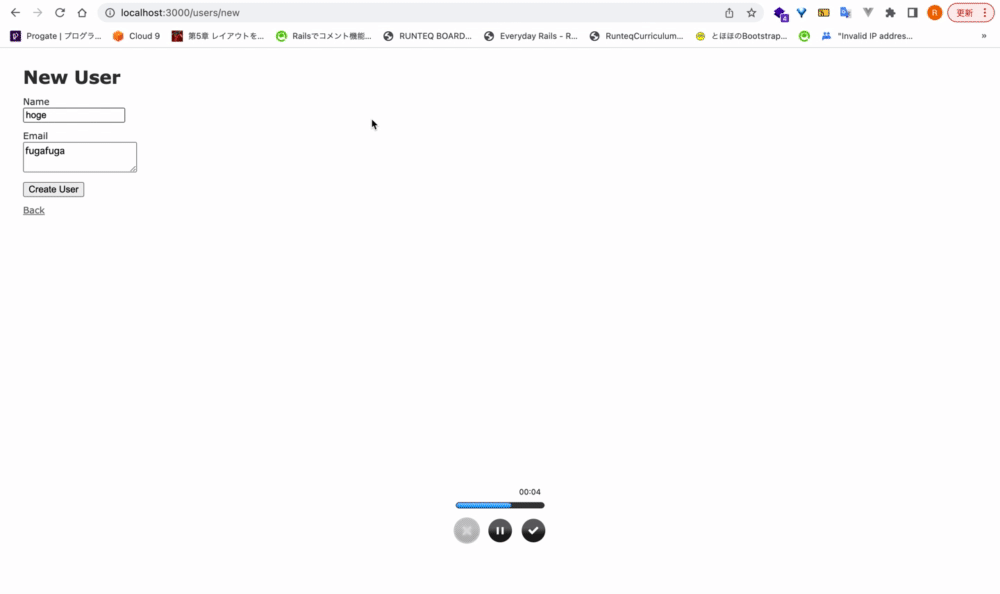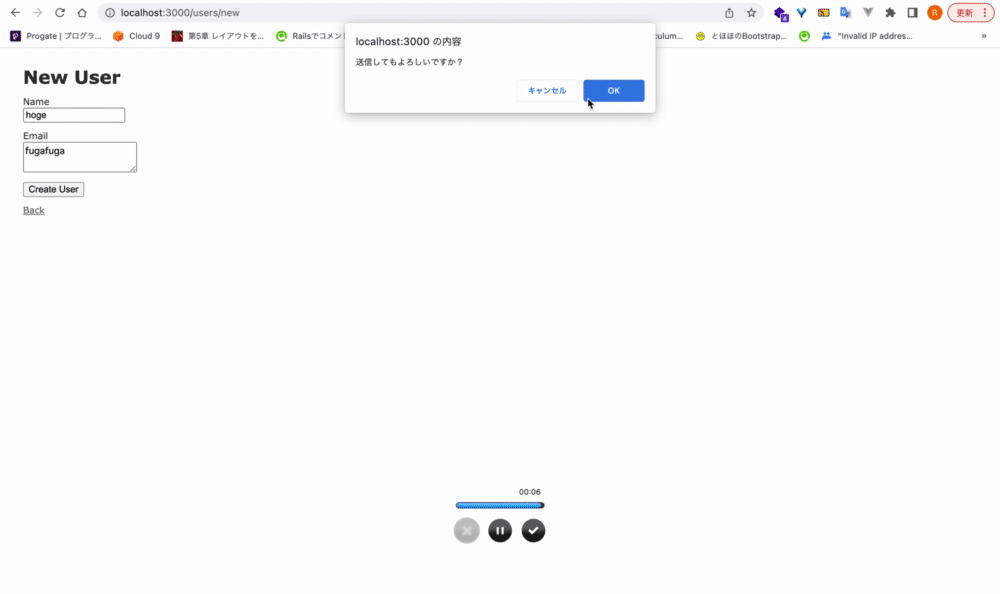
dataをキーとして、オブジェクト形式で渡してあげることで、JavaScriptを書かなくても簡単に実装できる。
2. Ajaxを手軽に実装できる
form_withは、デフォルトでAjaxができるようになっている。local: trueをつけると通常の同期通信となる。
2.Turbolinks
Ajax通信で受け取ったレスポンスの情報を、bodyタグ内を入れ替え表示させる。高速でページ遷移を実現するライブラリ。
独自の発火イベント
bodyタグ内を入れ替えて表示する挙動により、一般的にページが読み込まれたときのDOMContentLoadedやonloadなどのイベントが使用できない。Turbolinks上では、独自のturbolinks:loadを活用する。
applicaiton.js
... document.addEventListener("turbolinks:load", () => { console.log("読み込みました") })

この他にもクリックされた時に発火される
turbolinks:clickや、キャッシュされたバージョンへのアクセス時、新しいバーションアクセス時と2回発火するturbolinks:renderなどの独自の発火イベントがある。
キャッシュの活用
ブラウザの「戻る」「進む」でページ遷移をすると、Restoration Visitsという仕組みにより、キャッシュがあればリクエストを行わずに参照し、なければ新しいページを読み込む挙動となっている。これにより、知覚的なパフォーマンスを向上させる狙いがある